Среднеквадратическое отклонение пример. Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации
Приближенный метод оценки колеблемости вариационного ряда - определение лимита и амплитуды, однако не учитывают значений вариант внутри ряда. Основной общепринятой мерой колеблемости количественного признака в пределах вариационного ряда является среднее квадратическое отклонение (σ - сигма) . Чем больше среднее квадратическое отклонение, тем степень колеблемости данного ряда выше.
Методика расчета среднего квадратического отклонения включает следующие этапы:
1. Находят среднюю арифметическую величину (Μ).
2. Определяют отклонения отдельных вариант от средней арифметической (d=V-M). В медицинской статистике отклонения от средней обозначаются как d (deviate). Сумма всех отклонений равняется нулю.
3. Возводят каждое отклонение в квадрат d 2 .
4. Перемножают квадраты отклонений на соответствующие частоты d 2 *p.
5. Находят сумму произведений å(d 2 *p)
6. Вычисляют среднее квадратическое отклонение по формуле:
При n больше 30,или при n меньше либо равно 30, где n - число всех вариант.
Значение среднего квадратичного отклонения:
1. Среднее квадратическое отклонение характеризует разброс вариант относительно средней величины (т.е. колеблемость вариационного ряда). Чем больше сигма, тем степень разнообразия данного ряда выше.
2. Среднее квадратичное отклонение используется для сравнительной оценки степени соответствия средней арифметической величины тому вариационному ряду, для которого она вычислена.
Вариации массовых явлений подчиняются закону нормального распределения. Кривая, отображающая это распределение, имеет вид плавной колоколообразной симметричной кривой (кривая Гаусса). Согласно теории вероятности в явлениях, подчиняющихся закону нормального распределения, между значениями средней арифметической и среднего квадратического отклонения существует строгая математическая зависимость. Теоретическое распределение вариант в однородном вариационном ряду подчиняется правилу трех сигм.
Если в системе прямоугольных координат на оси абсцисс отложить значения количественного признака (варианты), а на оси ординат - частоты встречаемости вариант в вариационном ряду, то по сторонам от средней арифметической равномерно располагаются варианты с большими и меньшими значениями.
Установлено, что при нормальном распределении признака:
68,3% значений вариант находится в пределах М±1s
95,5% значений вариант находится в пределах М±2s
99,7% значений вариант находится в пределах М±3s
3. Среднее квадратическое отлонение позволяет установить значения нормы для клинико-биологических показателей. В медицине интервал М±1s обычно принимается за пределы нормы для изучаемого явления. Отклонение оцениваемой величины от средней арифметической больше, чем на 1s указывает на отклонение изучаемого параметра от нормы.
4. В медицине правило трех сигм применяется в педиатрии для индивидуальной оценки уровня физического развития детей (метод сигмальных отклонений), для разработки стандартов детской одежды
5. Среднее квадратическое отклонение необходимо для характеристики степени разнообразия изучаемого признака и вычисления ошибки средней арифметической величины.
Величина среднего квадратического отклонения обычно используется для сравнения колеблемости однотипных рядов. Если сравниваются два ряда с разными признаками (рост и масса тела, средняя длительность лечения в стационаре и больничная летальность и т.д.), то непосредственное сопоставление размеров сигм невозможно, т.к. среднеквадратическое отклонение - именованная величина, выраженная в абсолютных числах. В этих случаях применяют коэффициент вариации (Cv) , представляющий собой относительную величину: процентное отношение среднего квадратического отклонения к средней арифметической.
Коэффициент вариации вычисляется по формуле:
Чем выше коэффициент вариации, тем большая изменчивость данного ряда. Считают, что коэффициент вариации свыше 30 % свидетельствует о качественной неоднородности совокупности.
Инструкция
Пусть имеется несколько чисел, характеризующих -либо однородные величины. Например, результаты измереений, взвешиваний, статистических наблюдений и т.п. Все представленные величины должны измеряться одной и той же измерения. Чтобы найти квадратичное отклонение, проделайте следующие действия.
Определите среднее арифметическое всех чисел: сложите все числа и разделите сумму на общее количество чисел.
Определите дисперсию (разброс) чисел: сложите квадраты найденных ранее отклонений и разделите полученную сумму на количество чисел.
В палате лежат семь больных с температурой 34, 35, 36, 37, 38, 39 и 40 градусов Цельсия.
Требуется определить среднее отклонение от средней .
Решение:
« по палате»: (34+35+36+37+38+39+40)/7=37 ºС;
Отклонения температур от среднего (в данном случае нормального значения): 34-37, 35-37, 36-37, 37-37, 38-37, 39-37, 40-37, получается: -3, -2, -1, 0, 1, 2, 3 (ºС);
Разделите полученную раннее сумму чисел на их количество. Для точности вычисления лучше воспользоваться калькулятором. Итог деления является средним арифметическим значением слагаемых чисел.
Внимательно отнеситесь ко всем этапам расчета, так как ошибка хоть в одном из вычислений приведет к неправильному итоговому показателю. Проверяйте полученные расчеты на каждом этапе. Среднее арифметическое число имеет тот же измеритель, что и слагаемые числа, то есть если вы определяете среднюю посещаемость , то все показатели у вас будут «человек».
Данный способ вычисления применяется только в математических и статистических расчетах. Так, например, среднего арифметического значения в информатике имеет другой алгоритм вычисления. Среднее арифметическое значение является очень условным показателем. Оно показывает вероятность того или иного события при условии, что у него только один фактор либо показатель. Для наиболее глубокого анализа необходимо учитывать множество факторов. Для этого применяется вычисление более общих величин.
Среднее арифметическое - одна из мер центральной тенденции, широко используемая в математике и статистических расчетах. Найти среднее арифметическое число для нескольких значений очень просто, но у каждой задачи есть свои нюансы, знать которые для выполнения верных расчетов просто необходимо.
Количественных результатов проведенных подобных опытов.
Как найти среднее арифметическое число
Поиск среднего арифметического числа для массива чисел следует начинать с определения алгебраической суммы этих значений. К примеру, если в массиве присутствуют числа 23, 43, 10, 74 и 34, то их алгебраическая сумма будет равна 184. При записи среднее арифметическое обозначается буквой μ (мю) или x (икс с чертой). Далее алгебраическую сумму следует разделить на количество чисел в массиве. В рассматриваемом примере чисел было пять, поэтому среднее арифметическое будет равно 184/5 и составит 36,8.Особенности работы с отрицательными числами
Если в массиве присутствуют отрицательные числа, то нахождение среднего арифметического значения происходит по аналогичному алгоритму. Разница имеется только при рассчетах в среде программирования, или же если в задаче есть дополнительные условия. В этих случаях нахождение среднего арифметического чисел с разными знаками сводится к трем действиям:1. Нахождение общего среднего арифметического числа стандартным методом;
2. Нахождение среднего арифметического отрицательным чисел.
3. Вычисление среднего арифметического положительных чисел.
Ответы каждого из действий записываются через запятую.
Натуральные и десятичные дроби
Если массив чисел представлен десятичными дробями, решение происходит по методу вычисления среднего арифметического целых чисел, но сокращение результата производится по требованиям задачи к точности ответа.При работе с натуральными дробями их следует привести к общему знаменателю, который умножается на количество чисел в массиве. В числителе ответа будет сумма приведенных числителей исходных дробных элементов.
В данной статье я расскажу о том, как найти среднеквадратическое отклонение . Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом (греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
- Определите среднее (простое среднее арифметическое ряда значений).
- Затем от каждого из значений отнимите среднее и возведите полученную разность в квадрат (получили квадрат разности ).
- Следующим шагом будет вычисление среднего арифметического полученных квадратов разностей (Почему именно квадратов вы сможете узнать ниже).
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение . Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего :

Наконец, чтобы вычислить дисперсию , каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Дисперсия мм 2 .
Таким образом, дисперсия составляет 21704 мм 2 .
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
Мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки =  мм 2 .
мм 2 .
При этом стандартное отклонение по выборке равно  мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
 .
.
Для второго примера получится:
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал , Сергей Валерьевич
Определяется как обобщающая характеристика размеров вариации признака в совокупности. Оно равно квадратному корню из среднего квадрата отклонений отдельных значений признака от средней арифметической, т.е. корень из и может быть найдена так:
1. Для первичного ряда:
2. Для вариационного ряда:

Преобразование формулы среднего квадратичного отклонени приводит ее к виду, более удобному для практических расчетов:
Среднее квадратичное отклонение определяет на сколько в среднем отклоняются конкретные варианты от их среднего значения, и к тому же является абсолютной мерой колеблемости признака и выражается в тех же единицах, что и варианты, и поэтому хорошо интерпретируется.
Примеры нахождения cреднего квадратического отклонения: ,
Для альтернативных признаков формула среднего квадратичного отклонения выглядит так:
![]()
где р - доля единиц в совокупности, обладающих определенным признаком;
q - доля единиц, не обладающих этим признаком.
Понятие среднего линейного отклонения
Среднее линейное отклонение определяется как средняя арифметическая абсолютных значений отклонений отдельных вариантов от .
1. Для первичного ряда:

2. Для вариационного ряда:
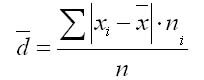
где сумма n - сумма частот вариационного ряда .
Пример нахождения cреднего линейного отклонения:
Преимущество среднего абсолютного отклонения как меры рассеивания перед размахом вариации, очевидно, так как эта мера основана на учете всех возможных отклонений. Но этот показатель имеет существенные недостатки. Произвольные отбрасывания алгебраических знаков отклонений могут привести к тому, что математические свойства этого показателя являются далеко не элементарными. Это сильно затрудняет использование среднего абсолютного отклонения при решении задач, связанных с вероятностными расчетами.
Поэтому среднее линейное отклонение как мера вариации признака применяется в статистической практике редко, а именно тогда, когда суммирование показателей без учета знаков имеет экономический смысл. С его помощью, например, анализируется оборот внешней торговли, состав работающих, ритмичность производства и т. д.
Среднее квадратическое
Среднее квадратическое применяется , например, для вычисления средней величины сторон n квадратных участков, средних диаметров стволов, труб и т. д. Она подразделяется на два вида.
Средняя квадратичная простая. Если при замене индивидуальных величин признака на среднюю величину необходимо сохранить неизменной сумму квадратов исходных величин, то средняя будет являться квадратичной средней величиной.
Она является квадратным корнем из частного от деления суммы квадратов отдельных значений признака на их число:
Средняя квадратичная взвешенная вычисляется по формуле:

где f - признак веса.
Средняя кубическая
Средняя кубическая применяется
, например, при определении средней длины стороны и кубов. Она подразделяется на два вида.
Средняя кубическая простая:


При расчете средних величин и дисперсии в интервальных рядах распределения истинные значения признака заменяются центральными значениями интервалов, которые отличны от средней арифметической значений, включенных в интервал. Это приводит к возникновению систематической погрешности при расчете дисперсии. В.Ф. Шеппард определил, что погрешность в расчете дисперсии , вызванная применением сгруппированных данных, составляет 1/12 квадрата величины интервала как в сторону повышения, так и в сторону понижения величины дисперсии.
Поправка Шеппарда должна применяться, если распределение близко к нормальному, относится к признаку с непрерывным характером вариации, построено по значительному количеству исходных данных (n > 500). Однако исходя из того, что в ряде случаев обе погрешности, действуя в разных направлениях компенсируют друг друга, можно иногда отказаться от введения поправок.
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность и тем более типичной будет средняя величина.
В практике статистики часто возникает необходимость сравнения вариаций различных признаков. Например, большой интерес представляет сравнение вариаций возраста рабочих и их квалификации, стажа работы и размера заработной платы, себестоимости и прибыли, стажа работы и производительности труда и т.д. Для таких сопоставлений показатели абсолютной колеблемости признаков непригодны: нельзя сравнивать колеблемость стажа работы, выраженного в годах, с вариацией заработной платы, выраженной в рублях.
Для осуществления таких сравнений, а также сравнений колеблемости одного и того же признака в нескольких совокупностях с разными средним арифметическим используется относительный показатель вариации - коэффициент вариации.
Структурные средние
Для характеристики центральной тенденции в статистических распределениях не редко рационально вместе со средней арифметической использовать некоторое значение признака X, которое в силу определенных особенностей расположения в ряду распределения может характеризовать его уровень.
Это особенно важно тогда, когда в ряду распределения крайние значения признака имеют нечеткие границы. В связи с этим точное определение средней арифметической, как правило, невозможно, либо очень сложно. В таких случаях средний уровень можно определить, взяв, например, значение признака, которое расположено в середине ряда частот или которое чаще всего встречается в текущем ряду.
Такие значения зависят только от характера частот т. е. от структуры распределения. Они типичны по месту расположения в ряду частот, поэтому такие значения рассматриваются в качестве характеристик центра распределения и поэтому получили определение структурных средних. Они применяются для изучения внутреннего строения и структуры рядов распределения значений признака. К таким показателям относятся .
Стандартное отклонение является одним из тех статистических терминов в корпоративном мире, которое позволяет поднять авторитет людей, сумевших удачно ввернуть его в ходе беседы или презентации, и оставляет смутное недопонимание тех, кто не знает, что это такое, но стесняется спросить. На самом деле большинство менеджеров не понимают концепцию стандартного отклонения и, если вы один из них, вам пора перестать жить во лжи. В сегодняшней статье я расскажу вам, как эта недооцененная статистическая мера позволит лучше понять данные, с которыми вы работаете.
Что измеряет стандартное отклонение?
Представьте, что вы владелец двух магазинов. И чтобы избежать потерь, важно, чтобы был четкий контроль остатков на складе. В попытке выяснить, кто из менеджеров лучше управляет запасами, вы решили проанализировать стоки последних шести недель. Средняя недельная стоимость стока обоих магазинов примерно одинакова и составляет около 32 условных единиц. На первый взгляд среднее значение стока показывает, что оба менеджера работают одинаково.

Но если внимательнее изучить деятельность второго магазина, можно убедится, что хотя среднее значение корректно, вариабельность стока очень высокая (от 10 до 58 у.е.). Таким образом, можно сделать вывод, что среднее значение не всегда правильно оценивает данные. Вот где на выручку приходит стандартное отклонение.
Стандартное отклонение показывает, как распределены значения относительно среднего в нашей . Другими словами, можно понять на сколько велик разброс величины стока от недели к неделе.
В нашем примере, мы воспользовались функцией Excel СТАНДОТКЛОН, чтобы рассчитать показатель стандартного отклонения вместе со средним.

В случае с первым менеджером, стандартное отклонение составило 2. Это говорит нам о том, что каждое значение в выборке в среднем откланяется на 2 от среднего значения. Хорошо ли это? Давайте рассмотрим вопрос под другим углом – стандартное отклонение равное 0, говорит нам о том, что каждое значение в выборке равно его среднему значению (в нашем случае, 32,2). Так, стандартное отклонение 2 ненамного отличается от 0, и указывает на то, что большинство значений находятся рядом со средним значением. Чем ближе стандартное отклонение к 0, тем надежнее среднее. Более того, стандартное отклонение близкое к 0, говорит о маленькой вариабельности данных. То есть, величина стока со стандартным отклонением 2, указывает на невероятную последовательность первого менеджера.
В случае со вторым магазином, стандартное отклонение составило 18,9. То есть стоимость стока в среднем отклоняется на величину 18,9 от среднего значения от недели к неделе. Сумасшедший разброс! Чем дальше стандартное отклонение от 0, тем менее точно среднее значение. В нашем случае, цифра 18,9 указывает на то, что среднему значению (32,8 у.е. в неделю) просто нельзя доверять. Оно также говорит нам о том, что еженедельная величина стока обладает большой вариабельностью.
Такова концепция стандартного отклонения в двух словах. Хотя оно не дает представление о других важных статистических измерениях (Мода, Медиана…), фактически стандартное отклонение играет решающую роль в большинстве статистических расчетов. Понимание принципов стандартного отклонения прольет свет на суть многих процессов вашей деятельности.
Как рассчитать стандартное отклонение?
Итак, теперь мы знаем, о чем говорит цифра стандартного отклонения. Давайте разберемся, как она считается.
Рассмотрим набор данных от 10 до 70 с шагом 10. Как видите, я уже рассчитал для них значение стандартного отклонения с помощью функции СТАНДОТКЛОН в ячейке H2 (оранжевым).

Ниже описаны шаги, которые предпринимает Excel, чтобы прийти к цифре 21,6.
Обратите внимание, что все расчеты визуализированы, для лучшего понимания. На самом деле в Excel расчет происходит мгновенно, оставляя все шаги за кулисами.
Для начала Excel находит среднее значение выборки. В нашем случае, среднее получилось равным 40, которое на следующем шаге отнимают от каждого значения выборки. Каждую полученную разницу возводят в квадрат и суммируют. У нас получилась сумма равная 2800, которую необходимо разделить на количество элементов выборки минус 1. Так как у нас 7 элементов, получается необходимо 2800 разделить на 6. Из полученного результата находим квадратный корень, это цифра будет стандартным отклонением.

Для тех, кому не совсем ясен принцип расчета стандартного отклонения с помощью визуализации, привожу математическую интерпретацию нахождения данного значения.

Функции расчета стандартного отклонения в Excel
В Excel присутствует несколько разновидностей формул стандартного отклонения. Вам достаточно набрать =СТАНДОТКЛОН и вы сами в этом убедитесь.

Стоит отметить, что функции СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г (первая и вторая функция в списке) дублируют функции СТАНДОТКЛОН и СТАНДОТКЛОНП (пятая и шестая функция в списке), соответственно, которые были оставлены для совместимости с более ранними версиями Excel.
Вообще разница в окончаниях.В и.Г функций указывают на принцип расчета стандартного отклонения выборки или генеральной совокупности. Разницу между двумя этими массивами я уже объяснял в предыдущей .
Особенностью функций СТАНДОТКЛОНА и СТАНДОТКЛОНПА (третья и четвертая функция в списке), является то, что при расчете стандартного отклонения массива в расчет принимаются логические и текстовые значения. Текстовые и истинные логические значения равняются 1, а ложные логические значения равняются 0. Мне трудно представить ситуацию, когда бы мне могли понадобится эти две функции, поэтому, думаю, что их можно игнорировать.